TAG: Tangential Amplifying Guidance
for
Hallucination-Resistant Sampling

Abstract
Diffusion models achieve state-of-the-art image generation but often produce semantic inconsistencies, or hallucinations. Existing inference-time guidance methods rely on external signals or architectural modifications, adding computational overhead. We propose Tangential Amplifying Guidance (TAG), a training-free, architecture-agnostic, plug-and-play guidance method that operates purely on trajectory signals. TAG uses an intermediate sample as a projection basis and amplifies the tangential components of the estimated score to correct the sampling trajectory. A first-order Taylor analysis shows that this steers the state toward higher-probability regions of the data manifold, reducing inconsistencies and improving fidelity while adding negligible overhead to existing samplers.
Why TAG? The Hallucination Problem
Diffusion samplers often produce outputs that violate the data distribution: mixed-up objects, anatomically implausible structures, mismatched attributes. The root cause is mode interpolation — trajectories drifting through low-density valleys between modes of the data distribution. Inference-time guidance such as classifier-free guidance (CFG) is the standard remedy, but most variants share a structural limitation:
They are geometry-unaware. CFG applies a single scalar magnification to the conditional−unconditional residual, with no regard for the local directional structure of the data distribution at each noise level. This can inadvertently distort the denoising trajectory, especially when the residual contains components that pull the state off the manifold.
TAG takes a different view. Building on Tweedie's identity, we decompose each update into components that move along the data manifold (tangential) and those that move across the prescribed noise schedule (radial). The tangential component carries rich structural information about the data — amplifying it sharpens semantics without breaking the schedule.
How TAG Works
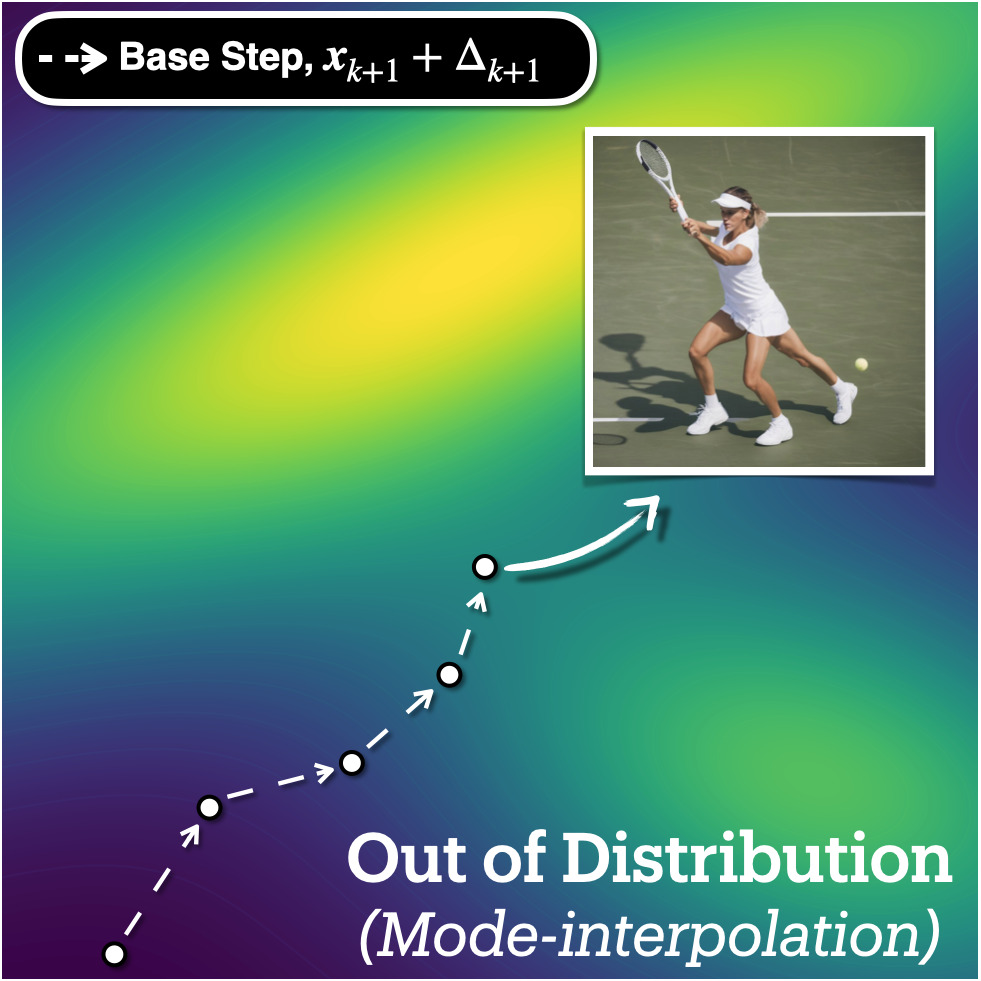
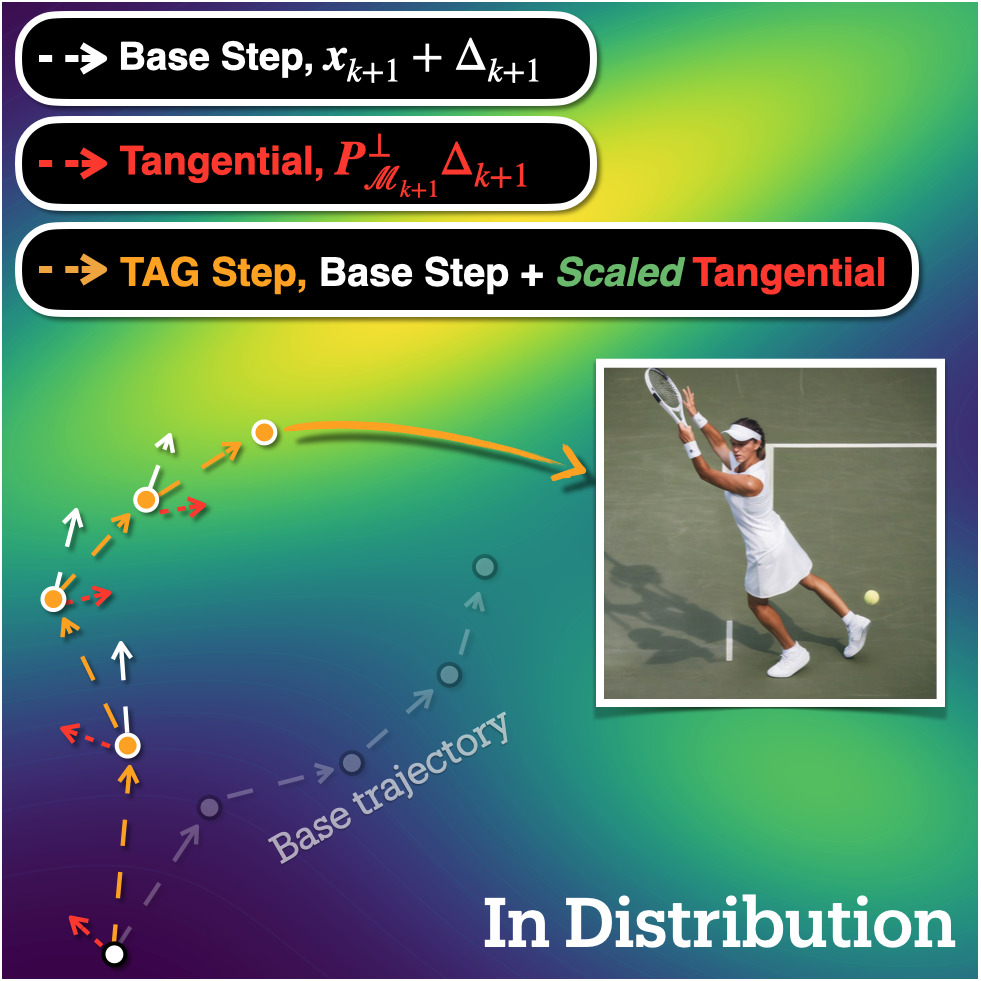
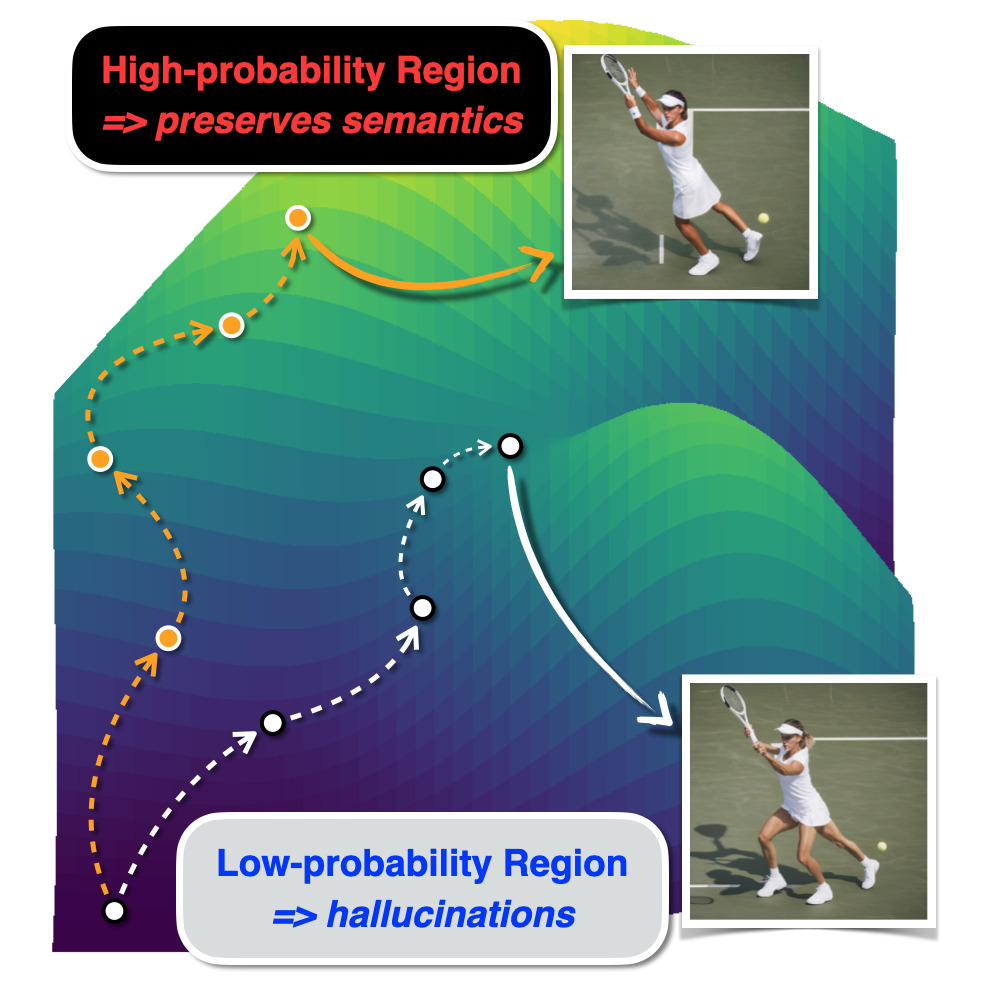
Conceptual view of TAG. On the latent sphere, TAG splits the base increment $\Delta_{k+1}$ into a parallel part $P_{\mathcal{M}}\Delta$ and an orthogonal (tangential) part $P^{\perp}_{\mathcal{M}}\Delta$, then amplifies only the tangential part — keeping the radial schedule intact while steering the trajectory toward higher-density regions of the data manifold.
Step 1 — A base update from any sampler.
At noise level $t_{k+1}$, the denoiser predicts $\varepsilon_{k+1}=\epsilon_\theta(x_{k+1},t_{k+1})$, and a base solver (e.g., DDIM, EDM) produces a provisional next state $\tilde{x}_k$. The base increment is
Step 2 — Decompose on the latent sphere.
Using the unit vector $\widehat{x}_{k+1}=x_{k+1}/\lVert x_{k+1}\rVert_2$, define the projectors $P_{\mathcal{M}}=\widehat{x}\widehat{x}^\top$ (radial / parallel) and $P^{\perp}_{\mathcal{M}}=I-P_{\mathcal{M}}$ (tangential / orthogonal). This splits the update into two interpretable pieces:
- Parallel $P_{\mathcal{M}}\Delta_{k+1}$ — the part that follows the prescribed noise schedule.
- Tangential $P^{\perp}_{\mathcal{M}}\Delta_{k+1}$ — the part that moves along the data manifold and carries semantic structure.
Step 3 — Amplify only the tangential part.
The TAG update rule, with a single hyperparameter $\eta\ge1$:
That's it. No extra forward passes, no second network, no schedule change. The radial component is preserved exactly; only the data-aligned direction is sharpened.
Theoretical Insight
We cast inference-time guidance as locally maximizing the log-likelihood under a bounded-step constraint. A first-order Taylor analysis of $\log p(\cdot\mid t_{k+1})$ gives a clean gain for a TAG update:
Proposition (informal). Increasing $\eta$ monotonically raises $G(\eta)$ — so TAG steers the sampler toward higher-density regions of the data manifold.
Why only the tangential part? Amplifying the radial (normal) part would multiply the radial first-order change, breaking one-step calibration under the VP / DDIM schedule and inducing over-smoothing. TAG's tangential boost preserves the radial first-order term exactly:
So TAG improves alignment without disturbing the schedule that the underlying sampler was trained for.
Results
TAG plugs into pretrained Stable Diffusion backbones with no training, no architecture change, and zero extra denoiser calls. The two main quantitative results on COCO 2014 — unconditional generation (Tab. 1) and conditional T2I generation (Tab. 2) — are reproduced below. Pink rows are TAG; bold marks the best per column within each backbone pair.
Table 1 — Unconditional Generation
SD-series on COCO 2014.
| Method | FID ↓ | IS ↑ | AES ↑ | CMMD ↓ |
|---|---|---|---|---|
| SD v1.5 | 58.41 | 15.59 | 5.003 | 1.069 |
| TAG v1.5 | 46.20 | 16.77 | 5.064 | 0.778 |
| SD v2.1 | 78.54 | 12.52 | 5.299 | 1.395 |
| TAG v2.1 | 59.94 | 13.36 | 5.320 | 1.122 |
| SDXL | 119.14 | 9.08 | 5.645 | 2.474 |
| TAG XL | 90.71 | 8.91 | 5.577 | 2.201 |
| SD3 | 84.26 | 11.53 | 5.261 | 1.671 |
| TAG 3 | 79.11 | 11.73 | 5.365 | 1.564 |
Table 2 — Conditional (T2I) Generation
SD-series on COCO 2014.
| Method | FID ↓ | ImageReward ↑ | CLIP ↑ |
|---|---|---|---|
| SD v1.5 | 33.49 | −0.342 | 25.00 |
| TAG v1.5 | 26.61 | −0.339 | 25.09 |
| SD v2.1 | 26.12 | 0.143 | 25.35 |
| TAG v2.1 | 21.59 | 0.424 | 26.16 |
| SDXL | 29.28 | 0.274 | 25.41 |
| TAG XL | 28.53 | 0.292 | 25.49 |
| SD3 | 29.02 | 1.030 | 26.39 |
| TAG 3 | 27.54 | 1.043 | 26.56 |
TAG consistently improves FID and CMMD on the unconditional setting across all backbones without extra NFEs, and improves both fidelity (FID) and prompt alignment (ImageReward, CLIP) on the conditional setting. Full tables — PAG / SEG plug-and-play stacks, hallucination-oriented T2I-CompBench, geometry-aware CFG variants (TCFG / APG), Qwen-Image, Wan2.2 video, and efficiency overhead — are in the paper.
Qualitative Comparison
Four settings, side by side: unconditional SD3, conditional SDXL, and plug-and-play stacks PAG + SDXL and SEG + SDXL. The top row is the baseline; the bottom row is the same prompt with TAG added. TAG sharpens semantics and resolves structural artifacts (blob-like formations, miscounted limbs, action-binding errors) without changing the architecture or schedule.
| Baseline |  |
 |
 |
 |
 |
 |
 |
 |
|
|---|---|---|---|---|---|---|---|---|---|
| + TAG |  |
 |
 |
 |
 |
 |
 |
 |
|
| Unconditional (SD3) | Conditional (SDXL) | + PAG (SDXL) | + SEG (SDXL) | ||||||
Left four columns: TAG enhances detail and coherence under both unconditional and conditional generation. Right four columns: TAG composes plug-and-play with existing guidance methods (PAG, SEG) to further improve their outputs.
BibTeX
@inproceedings{
cho2026tag,
title={{TAG}: Tangential Amplifying Guidance for Hallucination-Resistant Sampling},
author={Hyunmin Cho and Donghoon Ahn and Susung Hong and Jee Eun Kim and Seungryong Kim and Kyong Hwan Jin},
booktitle={Forty-third International Conference on Machine Learning},
year={2026},
url={https://openreview.net/forum?id=1XJqPy2LhA}
}